

Oversampling vs Undersampling dalam Mengatasi Ketidakseimbangan Data
Ketidakseimbangan data terjadi ketika jumlah contoh dalam satu kelas jauh lebih besar dibandingkan dengan jumlah contoh dalam kelas lainnya dalam sebuah dataset. Misalnya, dalam sebuah dataset untuk mendeteksi penipuan kartu kredit, jumlah transaksi yang sah jauh lebih banyak dibandingkan dengan transaksi yang penipuan. Ketidakseimbangan ini dapat menyebabkan model machine learning cenderung bias terhadap kelas mayoritas, sehingga mengabaikan atau tidak mengenali kelas minoritas dengan baik. Akibatnya, model mungkin menunjukkan kinerja yang buruk dalam mendeteksi contoh dari kelas minoritas.
Ada dua aspek pendekatan dalam menangani ketidakseimbangan data yaitu data level dan algoritma. Pendekatan data level yaitu mengubah distribusi dataset dengan metode sampling yaitu oversampling atau meningkatkan jumlah sampel pada kelas minoritas dan undersampling atau mengurangi jumlah sampel dari kelas mayoritas, dan atau dengan kombinasi keduanya. Sedangkan pendekatan algoritma yaitu dengan mendesign algoritma baru atau meningkatkan algoritma yang sudah ada. Teknik yang diklasifikasikan sebagai pendekatan algorithm level diantaranya adalah algoritma adaptive boosting, bagging, cost-sensitive, dan active learning.
Dalam artikel ini kita hanya akan membahas penanganan ketidakseimbangan data dalam data level yaitu dengan oversampling dan undersampling.
Oversampling
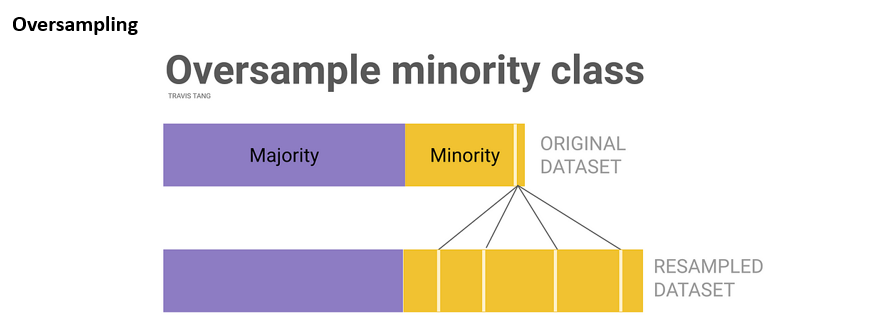
Sumber: https://towardsdatascience.com/class-imbalance-strategies-a-visual-guide-with-code-8bc8fae71e1a
Oversampling adalah teknik untuk mengatasi ketidakseimbangan data dengan menambah jumlah contoh dari kelas minoritas. Contoh yang sering digunakan adalah Synthetic Minority Over-sampling Technique (SMOTE) atau dapat juga menggunakan Random Oversampling (ROS) dan Adaptive Synthetic Sampling (ADASYN). Algoritma ini akan menciptakan sintetis instance baru dari kelas minoritas.
Undersampling
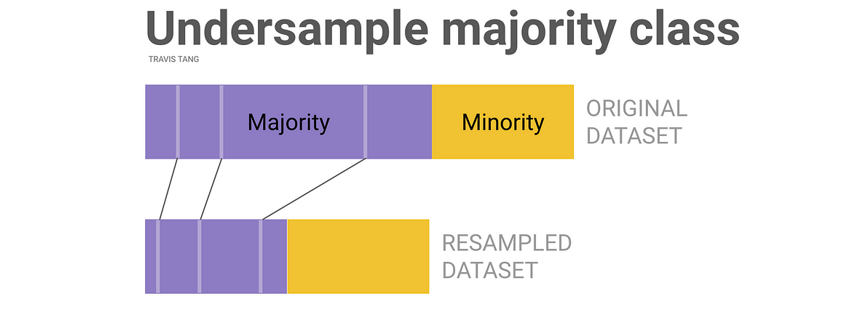
Sumber: https://towardsdatascience.com/class-imbalance-strategies-a-visual-guide-with-code-8bc8fae71e1a
Undersampling adalah teknik yang mengurangi jumlah contoh dari kelas mayoritas untuk menyeimbangkan dataset. Ini dilakukan dengan mengambil subset dari kelas mayoritas sehingga proporsinya lebih seimbang dengan kelas minoritas.
Oversampling cocok digunakan untuk data dengan jumlah instance yang sedikit. Sedangkan undersampling dapat digunakan untuk dataset dengan jumlah data yang besar dan tidak cocok untuk dataset dengan jumlah yang kecil. Selain itu, undersampling memungkinkan juga untuk kehilangan informasi penting dikarenakan proses pengurangan jumlah data. Hal penting lainnya dalam Class Imbalance Learning adalah evaluation matric yang digunakan. Dalam Class Imbalance Learning, membutuhkan evaluation matric yang lain selain akurasi. Evaluation matric lain yang dapat digunakan yaitu precision, recall, f1-score, dan AUC-ROC.
Sumber:
https://towardsdatascience.com/class-imbalance-strategies-a-visual-guide-with-code-8bc8fae71e1a
Comments :