Tutorial Menggunakan WEKA untuk Clustering

Selain dengan menggunakan RapidMiner Studio atau Altair AI Studio, terdapat software lain yang dapat dengan mudah digunakan untuk knowledge analysis yaitu Wakaito Environment for Knowledge Analysis (WEKA). WEKA merupakan perangkat lunak open-source yang digunakan untuk machine learning dan data mining. Dikembangkan oleh Universitas Waikato di Selandia Baru, WEKA menyediakan berbagai algoritma untuk analisis data, termasuk classification, regression, clustering, dan feature selection. WEKA dapat didownload melalui link berikut: https://waikato.github.io/weka-wiki/documentation/
Berikut merupakan tutorial Classification dengan menggunakan WEKA.
1. Setelah aplikasi WEKA dijalankan, pilih WEKA Workbench
2. Berikut merupakan tampilan GUI dari WEKA Workbench
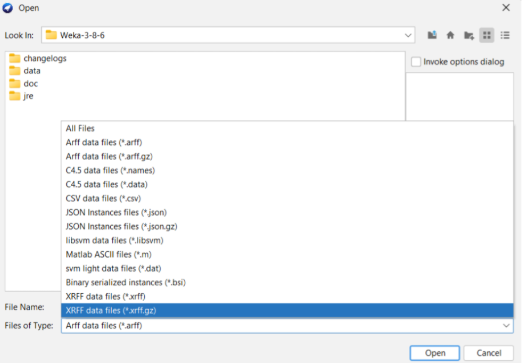
3. Setelah itu, pilih Open File dan pilih dataset yang ingin dianalisis. WEKA dapat mengolah dataset dengan ekstensi standar dataset yaitu CSV.
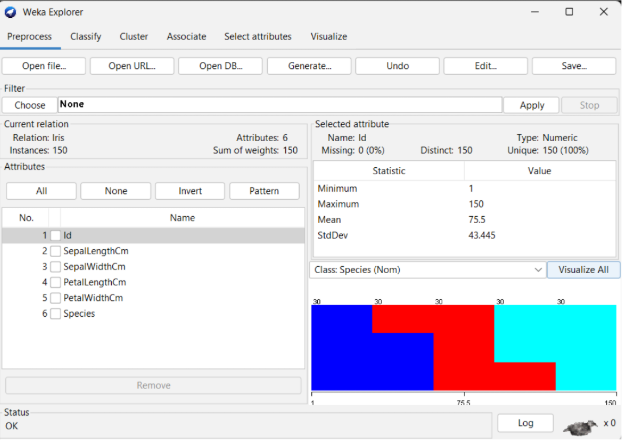
Berikut merupakan tampilan ketika file berhasil diinputkan.
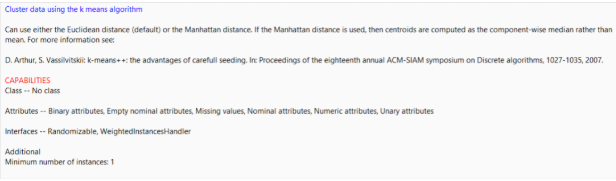
4. Pilih menu Cluster, dan pilih salah satu algoritma Clustering yang diinginkan. Dalam tutorial ini akan menggunakan K-Means Clustering. Keterangan tentang algoritma yang digunakan dapat diperoleh dengan mendekatkan kursor pada algoritma yang diinginkan. Berikut merupakan keterangan dari algoritma K-Means yang digunakan oleh WEKA.
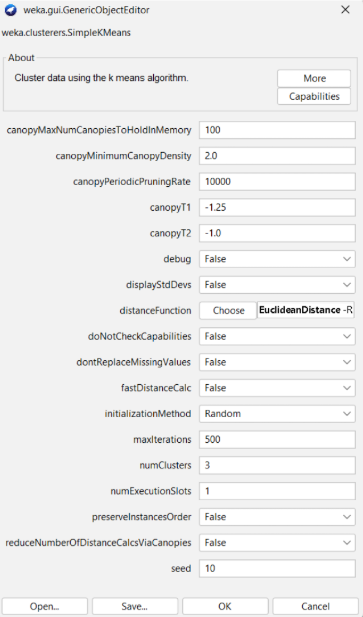
5. Pengguna dapat melakukan pengubahan parameter algoritma yang digunakan dengan melakukan klik pada algoritma yang sudah dipilih.

Setelah itu akan muncul parameter K-Means Clustering. Dalam tutorial ini, akan menggunakan parameter standar yang digunakan WEKA untuk K-Means Clustering yaitu untuk mengukur jarak menggunakan Euclidean Distance, inisialisasi dengan random, jumlah maksimal iterasi 500 dan jumlah cluster adalah tiga.
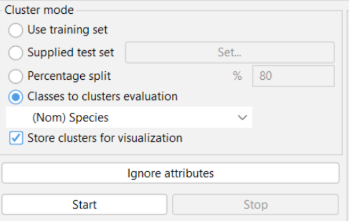
6. Langkah berikutnya yaitu memilih Cluster Mode. Dalam Tutorial ini, dikarenakan Iris Dataset merupakan dataset yang memiliki label atau class, maka kita akan menggunakan class ini untuk cluster evaluation.
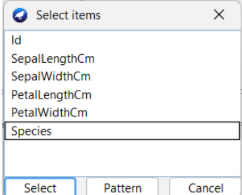
Selain itu kita dapat melakukan ignore attributes atau membiarkan atributnya. Dalam tutorial ini, karena kita menggunakan metode Clustering, maka kita dapat ignore untuk attribute classnya yaitu Species.
7. Setelah itu klik Start. Hasil akan tampil pada Classifier Output. Pada Cluster Output terdapat informasi dataset, Cluster Model, hingga summary hasilnya.
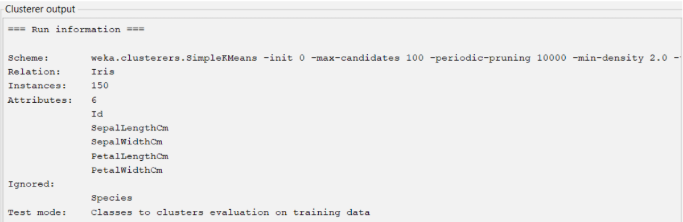
8. Berikut merupakan Informasi Dataset dan model yang digunakan
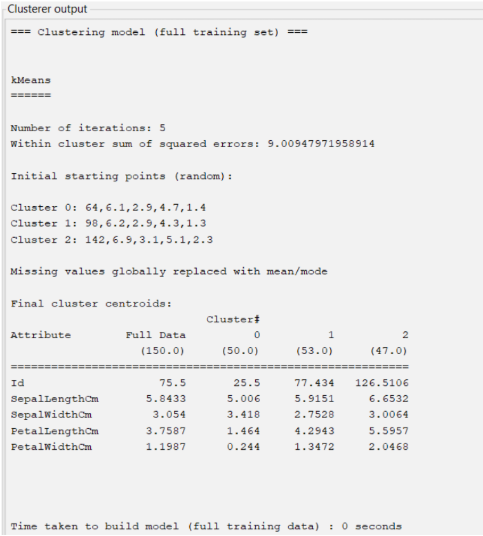
9. Berikut merupakan keterangan model yang digunakan.
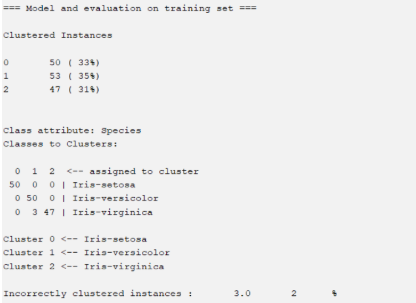
10. Berikut merupakan Summary model. Hasil evaluasi model dengan menggunakan WEKA sangat lengkap. Dikarenakan kita tadi menggunakan Classes to Cluster Evaluation, maka terdapat hasil analisis class mana yang di-clusterkan pada class yang salah.
Referensi: https://waikato.github.io/weka-wiki/documentation/