

MapReduce di Hadoop: Rahasia di Balik Pengolahan Data Skala Besar
Di era digital saat ini, data menjadi salah satu aset paling berharga bagi organisasi. Dengan meningkatnya volume data yang dihasilkan setiap hari, kemampuan untuk mengolah dan menganalisis data skala besar menjadi kebutuhan utama. Hadoop, sebagai salah satu framework big data terpopuler, menawarkan solusi untuk tantangan ini melalui MapReduce, sebuah model pemrograman yang dirancang khusus untuk memproses data dalam jumlah besar secara efisien dan terdistribusi.
Apa Itu MapReduce? MapReduce adalah sebuah model pemrograman yang pertama kali dikembangkan oleh Google. Model ini dirancang untuk memproses data dalam skala besar dengan memanfaatkan kemampuan komputasi paralel dalam lingkungan terdistribusi. Prosesnya memungkinkan data yang sangat besar diolah secara efisien dengan membagi tugas ke berbagai mesin atau node.
Manfaat Map Reduce
- Memungkinkan pengolahan data dalam skala besar secara efisien.
- Dapat diimplementasikan dalam lingkungan komputasi terdistribusi untuk meningkatkan kecepatan dan kinerja pengolahan data.
- Dapat diterapkan pada berbagai jenis data dan digunakan dalam berbagai aplikasi seperti analisis teks, pemrosesan log, dan lain sebagainya.
Proses Map Reduce untuk Word Count
- Input: Dokumen atau data yang akan dihitung jumlah katanya.
- Splitting: Dokumen dibagi menjadi bagian-bagian kecil, yang disebut split. Setiap split berisi sebagian kecil dari dokumen.
- Mapping: Setiap kata dalam setiap split diidentifikasi dan dipetakan menjadi pasangan (kata, 1). Misalnya, jika dokumen berisi kata “hello world”, maka hasil mappingnya adalah (“hello”, 1), (“world”, 1).
- Shuffling: Pasangan (kata, 1) yang sama dikumpulkan bersama-sama. Misalnya, semua pasangan (“hello”, 1) dan (“world”, 1) yang dihasilkan dari mapping akan dikumpulkan bersama-sama.
- Reducing: Setiap pasangan (kata, 1) yang telah dikumpulkan dijumlahkan sehingga menjadi pasangan (kata, jumlah). Misalnya, jika terdapat beberapa pasangan (“hello”, 1) dan (“hello”, 1), maka hasil reducingnya adalah (“hello”, 2).
- Final Result: Hasil akhir dari proses Word Count adalah daftar pasangan (kata, jumlah) yang digabungkan. Misalnya, (“hello”, 2), (“world”, 1).
Contoh Gambar Map Reduce
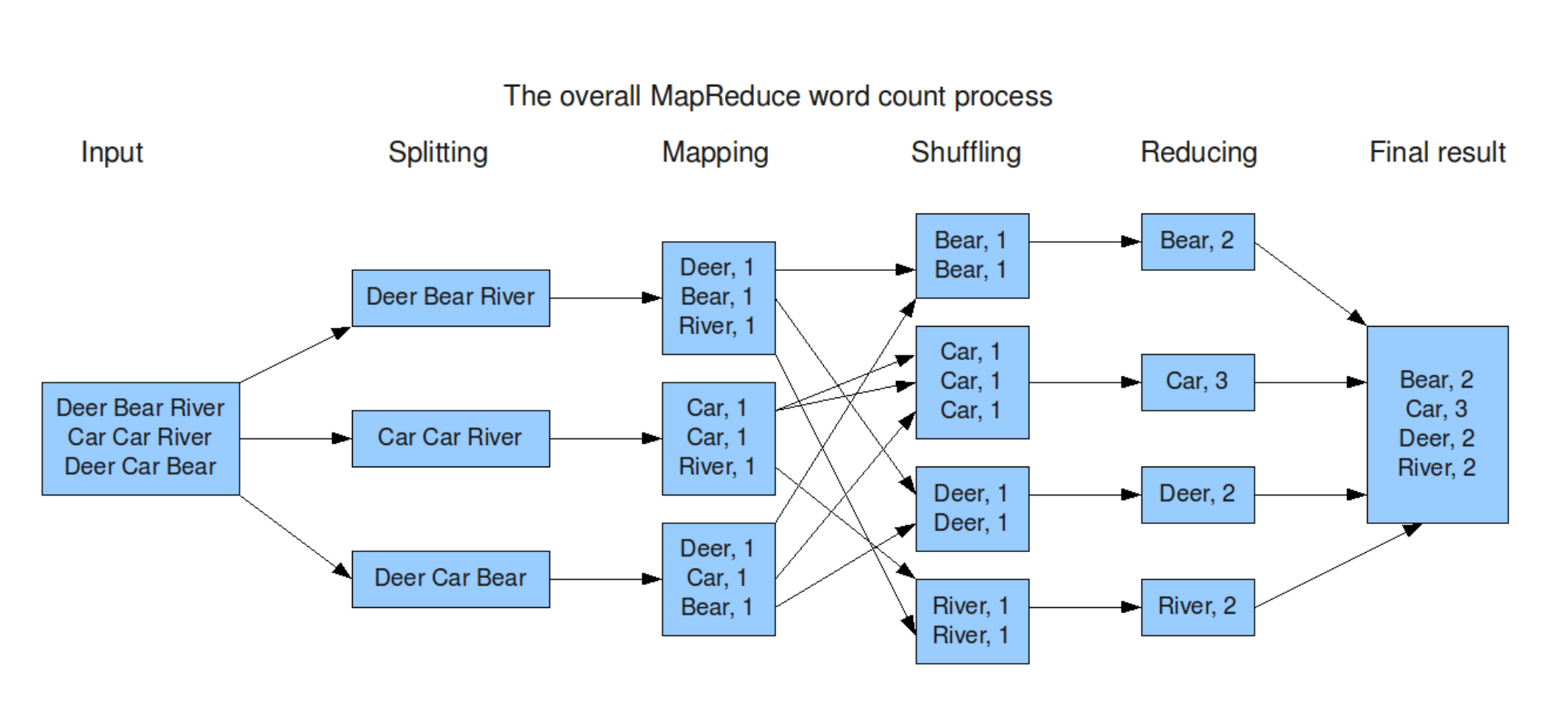
Contoh Implementasi MapReduce MapReduce dapat diterapkan dalam berbagai skenario, seperti:
- Analisis Log Server: Menghitung jumlah pengunjung atau pola akses pada situs web.
- Analisis Media Sosial: Menganalisis miliaran postingan untuk memahami tren atau sentimen.
- Pemrosesan Data Genom: Membantu analisis data biologis dalam skala besar.
Kesimpulan
Dengan memahami konsep dasar MapReduce, kita dapat mengolah data dalam skala besar dengan lebih efisien dan efektif. Dengan membagi tugas menjadi proses paralel, MapReduce mengatasi tantangan yang muncul dari volume data yang besar. Konsep ini juga menjadi dasar bagi pengembangan berbagai framework pengolahan data terdistribusi seperti Apache Hadoop.