

How Machine Learning Help in Detecting Credit Card Fraud
Some credit card owners may have experienced their purchase or transaction declined especially if the transaction is in unusually big amount. In order to solve it, the credit card owner must call their credit card company to authorize the transaction. Although it can be seen as a hassle, but this proves the length that credit card company went through to ensure the safety of its customer from fraud. This will be super helpful if someone stole your credit card and make unauthorized purchase. You may wonder how they can recognize that you are the one using the credit card, whether there is someone behind the screen checking all the transaction made or if a robot did the job. The latter is half correct, robot consist of program and codes just like the machine learning that credit card company use in detecting credit card fraud.
The underlying analysis in detecting credit card fraud is the cardholder’ spending behaviour. There are 5 main variable types used in the analysis merchant type statistics, all transaction statistics, regional statistics, time-based number of transaction statistics and time-based amount statistics. The variables help in determining the cardholder’ general profile. The pattern from each statistic will be analysed using data mining, one of the machine learning techniques. Data mining allow user to extract information and discover pattern from data set. Data mining consist of many types of method and algorithm according to the objective. For predictions task, the method is divided into classification, regression, and time series. Usually in detecting credit card fraud risk, classification method is used. Classification has different type of algorithm such as decision trees, neural networks, support vector machine, Naïve Bayes, etc.
In order to explain the system better, we will use a case of using random forest algorithm in data mining classification. Especially since random forest showed the best result in predicting fraud compared to other algorithms in research done in 2019. Random forest is an algorithm that can be used in classification or regression, it is named ‘forest’ because it consists of many decision trees. The decision trees will be run at the same time and the output will be determined by most decision tree output. Image below will help to visualize the algorithm.
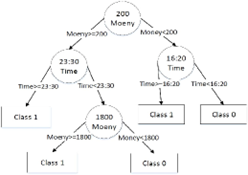
The example decision tree besides, classify based on the amount spent and the time of the transaction. The class 1 represent fraudulent transaction meanwhile the class21 represent genuine transaction. If a transaction amount is $1000 and done at 3 AM then the transaction according to the decision tree will be considered fraudulent. This is just a simple model compared to the one used by the credit card company in detecting credit card fraud. There are many variables being considered and data used.
References:
https://www.semanticscholar.org/paper/Random-forest-for-credit-card-fraud-detection-Xuan-Liu/a5562332dd970fed3d6c0cd3327d9847af117c96
https://ieeexplore.ieee.org/abstract/document/8123782
https://ieeexplore.ieee.org/abstract/document/8717766
Comments :