

Data Mining SEMMA
In addressing the more complex business problems in this modern era, data mining has undoubtedly gained its popularity as a tool in tending those perplexing issues. Not only as a solver of pressing problems, data mining has also opened up many opportunities as it has been proven to be effective and accommodating in numerous areas: banking, manufacturing and production, insurance, healthcare, etc. It uncovers previously unknown patterns making it useful for business advantage. By applying data mining tools (i.e. CRISP-DM, SEMMA, etc.), to these enormous and rich information sources, provides them with insights—useful for preparations on the anticipated future, creating a holistic view for better and quicker response and management.
As one of the standard process for data mining, SEMMA, from SAS Institute, alludes to the center process of conducting data mining. Abbreviated from sample, explore, modify, model, and assess, SEMMA starts off with a statistically representative sample of data. Then, it applies exploratory and visualization techniques, followed by modifying variable representations, model variables to foresee results, and finally affirming model’s precision. Figure 1 shows the data mining process on how SEMMA works and then followed by a more detailed explanation for each phase.
Figure 1 – SEMMA Data Mining Process
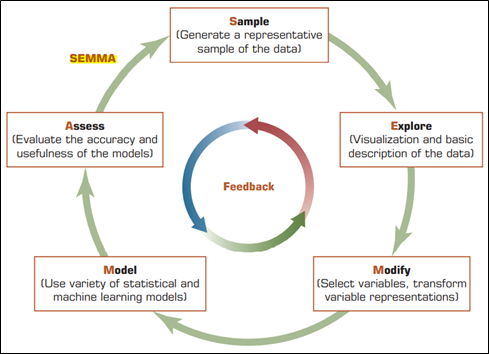
Source: Sharda, R., Delen, D., Turban, E. (2018). Big data Intelligence, Analytics, and Data Science: A Managerial Perspective. 04. Pearson Education. New Jersey. ISBN: 9780134633282.
- Sample – Generating data in this phase could be optional. It involves extracting a large dataset so that a significant piece of information can be deducted formed by pattern. As a way to optimize cost and performance, the SAS Institute applies a dependable and statistically representative sample of complete detail information sources instead of mining whole volume of data.
- Explore – Data is explored by looking for unforeseen patterns and oddities. This could increase comprehension and ideas towards the data. Moreover, it also refines the disclosure process, because if there is no visualization, or visual itself is unclear, it can be done through statistical techniques (clustering, factor analysis, etc.).
- Modify – Data is modified by creating, selecting, and transforming variables to center the model selection, and any additional information or variables can be added necessarily to make information output for significant. Whenever new information is available, data mining methods can be updated or modified.
- Model – Data is modelled by permitting software to search for mix of data that dependably predicts an ideal result, in an automatic way. For example, statistical models such as time series analysis, memory-based reasoning, etc.
- Assess – Data is assessed by evaluating whether findings from the data is valuable enough (useful) and reliable. In this phase, data can also be gauged on how well it performs. If data model is valid, it should work just fine on both reserved sample and constructed sample.
On a side note, however, it is imperative to notice that prior to these phases of SEMMA, SEMMA itself is not merely an information mining technique. Specifically, it is a functional tool set developed by SAS Enterprise, rather than a broad range of data mining tool. It focuses on SAS Enterprise Miner software, which can be utilized as a major aspect of any iterative information mining system. To put it simply, SEMMA focuses on the model development aspects of data mining. Outcome of each stage in the SEMMA cycle can be assessed, which will be useful as the model developer can decide appropriate demonstration for new inquiries raised by past outcomes and results. With that, it can proceed back to the explore phase to get any extra refinement on the information.
References:
- Sharda, R., Delen, D., & Turban, E. (2018). Business intelligence, analytics, and data science: A managerial perspective. New York, NY: Pearson.
- Faculty.smu.edu (2020). Retrieved from http://faculty.smu.edu/tfomby/eco5385_eco6380/data/SPSS/SAS%20_%20SEMMA.pdf
Comments :