

Data Lake
Data Lake adalah gudang penyimpanan yang dapat menyimpan data terstruktur, semi-terstruktur, dan tidak terstruktur dalam jumlah besar. Ini adalah tempat untuk menyimpan semua jenis data dalam format aslinya tanpa batas tetap pada ukuran atau file akun. Ini menawarkan kuantitas data yang tinggi untuk meningkatkan kinerja analitik dan integrasi asli.
Data Lake merupakan cara yang hemat biaya karena menyimpan semua data dari suatu organisasi yang akan diproses nantinya. Seorang Riset Analis dapat berfokus pada penemuan pola-pola makna dalam data dan bukan data itu sendiri. Lain halnya dengan Data warehouse hierarkis di mana data disimpan dalam File dan Folder, Data Lake memiliki arsitektur datar. Setiap elemen data di Data Lake diberi pengidentifikasi unik dan diberi tag dengan satu set informasi metadata.
Tujuan utama dari membangun Data Lake adalah untuk menawarkan pandangan data yang belum diolah ke para ilmuwan atau peneliti data. Berikut ini alasan menggunakan Data Lake adalah:
- Dengan munculnya mesin penyimpanan seperti Hadoop, menyimpan informasi yang berbeda menjadi lebih Tidak perlu memodelkan data ke skema perusahaan secara meluas apabila dengan menggunakan Data Lake.
- Dengan peningkatan volume data, kualitas data, dan metadata, kualitas analisis juga meningkat.
- Data Lake juga menawarkan kecepatan proses dalam bisnis
- Pembelajaran mesin dan Kecerdasan Buatan dapat digunakan untuk membuat prediksi yang menguntungkan dan menawarkan keunggulan kompetitif bagi organisasi pelaksana.
Berikut ini adalah konsep-konsep kunci dari Data Lake yang perlu dipahami sepenuhnya untuk memahami Data Lake Architecture :
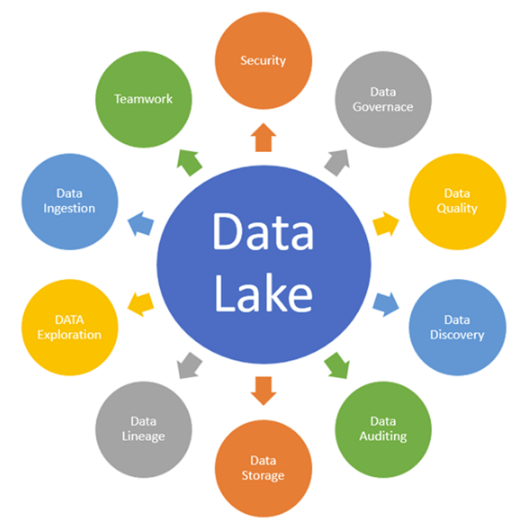
Gambar 1. Data Lake Concept
Berikut ini adalah penjelasan secara singkatnya :
- Data Ingestion (Penyerapan Data):
Penyerapan Data memungkinkan konektor untuk mendapatkan data dari sumber data yang berbeda dan memuat ke dalam Data Lake. Penyerapan Data mendukung:
- Semua jenis data terstruktur, semi terstruktur, dan tidak terstruktur.
- Beberapa konsumsi seperti Batch, Real-Time, Beban satu kali.
- Banyak jenis sumber data seperti Databases, Webservers, Emails, IoT, dan FTP.
- Data Storage (Penyimpanan data):
Penyimpanan data harus terukur, menawarkan penyimpanan hemat biaya dan memungkinkan akses cepat ke eksplorasi data dan harus mendukung berbagai format data.
- Data Governance (Tata Kelola Data):
Tata kelola data adalah proses mengelola ketersediaan, kegunaan, keamanan, dan integritas data yang digunakan dalam suatu organisasi.
- Security (Keamanan):
Keamanan perlu diterapkan di setiap lapisan Data Lake. Dimulai dengan storage, Unearthing, dan pemakaian data. Tujuan utamanya adalah menghentikan akses untuk pengguna yang tidak sah. Otentikasi, Kepemilikan Akun, Otorisasi dan Perlindungan Data adalah beberapa fitur penting dari keamanan Data Lake.
- Data Quality (Kualitas data):
Kualitas data merupakan komponen penting dari arsitektur Data Lake. Data digunakan untuk membentuk nilai bisnis. Mengekstrak wawasan dari data berkualitas buruk akan mengarah pada wawasan yang berkualitas rendah.
- Data Discovery (Penemuan Data):
Data Discovery adalah tahap penting lainnya sebelum Anda dapat mulai menyiapkan data atau analisis. Pada tahap ini, teknik penandaan digunakan untuk mengekspresikan pemahaman data, dengan mengatur dan menafsirkan data yang dicerna di Data Lake.
- Data Auditing (Audit Data):
Dua tugas utama dalam pengauditan Data adalah :
- Melacak perubahan pada set data kunci dan elemen kumpulan data penting
- Menangkap bagaimana / kapan / dan siapa yang berubah di dalam data tersebut.
Audit data membantu mengevaluasi risiko dan kepatuhan.
- Data Lineage :
Komponen ini berhubungan dengan asal data. Terutama berkaitan dengan tempat penggeraknya dari waktu ke waktu dan apa yang terjadi padanya. Hal ini memudahkan koreksi kesalahan dalam proses analisis data dari asal ke tujuan.
- Data Exploration (Eksplorasi Data) :
Hal ini adalah tahap awal analisis data. Proses ini membantu untuk mengidentifikasi kumpulan data yang tepat sangat penting sebelum memulai tahap selanjutnya. Semua komponen yang diberikan harus bekerja sama untuk memainkan bagian penting dalam arstitektur Data Lake dengan mudah berevolusi dan mengeksplorasi lingkungan.
Berikut ini adalah beberapa manfaat utama dalam menggunakan Data Lake:
- Membantu sepenuhnya dengan pengionisasi produk & analisis tingkat lanjut
- Menawarkan skalabilitas dan fleksibilitas yang hemat biaya
- Menawarkan nilai dari tipe data yang tak terbatas
- Mengurangi biaya kepemilikan jangka panjang
- Memungkinkan penyimpanan file yang ekonomis
- Cepat beradaptasi dengan perubahan
- Keuntungan utama dari data lake adalah sentralisasi sumber konten yang berbeda
- Pengguna dari berbagai departemen, dapat tersebar di seluruh dunia yang dapat memiliki akses fleksibel ke data
Referensi
Inmon, B. (2016). Data Lake Architecture. New Jersey USA: Technics Publications.