

Architectural Alternatives in Distributed Database
Architecturally, a distributed database system consists of a (possibly empty) set of query sites and a non-empty set of data sites. The data sites have data storage capability while the query sites do not. The latter only run the user interface (in addition to applications) in order to facilitate data access at data sites (Figure 1).
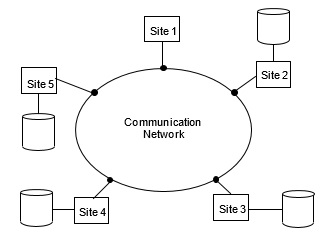
Figure 1. Distributed Database Environment
If the distributed database systems at various sites are autonomous and (possibly) exhibit some form of heterogeneity, they are referred to as multidatabase systems (see Multidatabase Systems) or federated database systems (see Federated Database Systems). If the data and DBMS functionality distribution is accomplished on a
multiprocessor computer, then it is referred to as a parallel database system (see Parallel Databases). These are different than a distributed database system where the logical integration among distributed data is tighter than is the case with multidatabase systems or federated database systems, but the physical control is looser than that in parallel
DBMSs.
There are a number of different architectural models for the development of a distributed DBMS, ranging from client/server systems [2], where the query sites correspond to clients while the data sites correspond to servers (see Client-Server Computing), to a peer-to-peer system where no distinction is made among the client machines and the server machines. These architectures differ with respect to the location where each DBMS function is provided.
In the case of client/server DBMSs, the server does most of the data management work. This means that all of query processing and optimization, transaction management and storage management is done at the server. The client, in addition to the application and the user interface, has a DBMS client module that is responsible for managing the data that is cached to the client and (sometimes) managing the transaction locks that may have been cached as well. A typical client/server functional distribution is given in Figure 2.
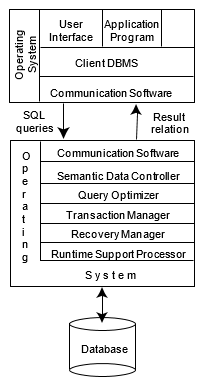
Figure 2. Client/Server Architecture
The simplest client/server architecture is a multiple-client/single-server system. From a data management perspective, this is not much different from centralized databases since database is stored on only one machine (the server) which also hosts the software to manage it. However, there are some important differences from centralized systems in the way transactions are executed and caches are managed. A more sophisticated client/server architecture is one where there are multiple serves in the system (the so-called multiple-client/multiple-server approach). In this case, two alternative maangement strategies are possible: either each DBMS client manages its own connection to the appropriate server or each client knows only its home server_ which then communicates with other servers as required. The former approach simplifies server code, but loads the client machines with additional responsibilities ( heavy client ) while the latter approach concentrates data management functionality at the servers and provides transparency of data access at the server interface ( ight client ).
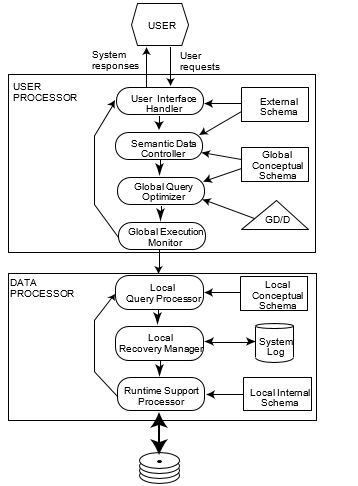
Figure 3. Peer-to-Peer Distributed DBMS Functionality
In the case of peer-to-peer systems, there is no distinction between clients and servers and each site in the system can perform the same functionality. It is still possible to separate the modules that serve user requests from others that manage data (see Figure 3), but this is only a logical separation and does not imply any functionality distribution. In executing queries (transactions), it is possible for the global query optimizer (global execution monitor) to communicate directly with the local query processors (local recovery managers) where parts of the query (transaction) are executed. Thus, the communication mechanism is more involved, leading to more complicated software structures.