

Six of the Best Open Source Data Mining Tools
Data mining itself is the process of analyzing data from different perspectives and summarizing it into useful information. In order to analyze all those data, we need data mining software which allows users to analyze data from many different dimensions or angles, categorize it, and summarize the relationships identified. Technically, data mining is the process of finding correlations or patterns among dozens of fields in large relational databases. There are six different open source data mining tools that we can use:
- RapidMiner is one of the top list in data mining tools. This tools offers advanced analytics through template-based frameworks. In addition, RapidMiner also provides functionality like data preprocessing and visualization, predictive analytics and statistical modeling, evaluation, and deployment. What makes it be the first out of the list is that it provides learning schemes, models and algorithms from WEKA and R scripts. RapidMiner also trusted by many company which are Samsung, BMW, CISCO, salesforce, KPMG, Domino’s, General Electric, AMNESTY INTERNATIONAL, Miele, SANOFI, Georgia-Pacific, and Barclays.RapidMiner also provides choices for the user, which are download the RapidMiner application or launch a pilot project and RapidMiner will find an expert for us.
 RapidMiner also has more functions to offer to accelerate the creation, delivery, and maintenance.
RapidMiner also has more functions to offer to accelerate the creation, delivery, and maintenance.
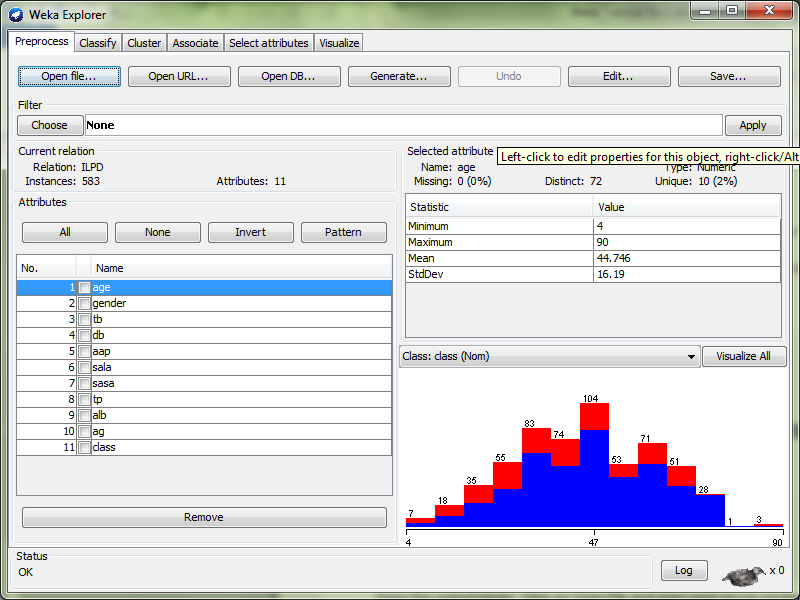
- WEKA primarily was developed for analyzing data from the agricultural domain. This tool is very sophisticated and used in many different applications including visualization and algorithms for data analysis and predictive modeling.
 WEKA supports several standard data mining tasks, including data preprocessing, clustering, classification, regression, visualization and feature selection.
WEKA supports several standard data mining tasks, including data preprocessing, clustering, classification, regression, visualization and feature selection.
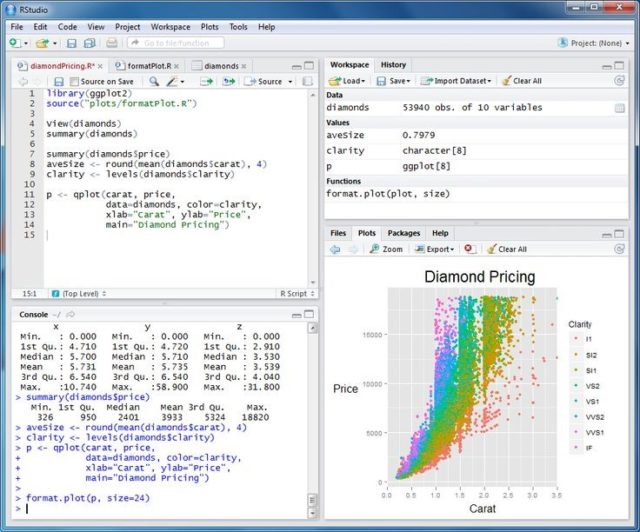
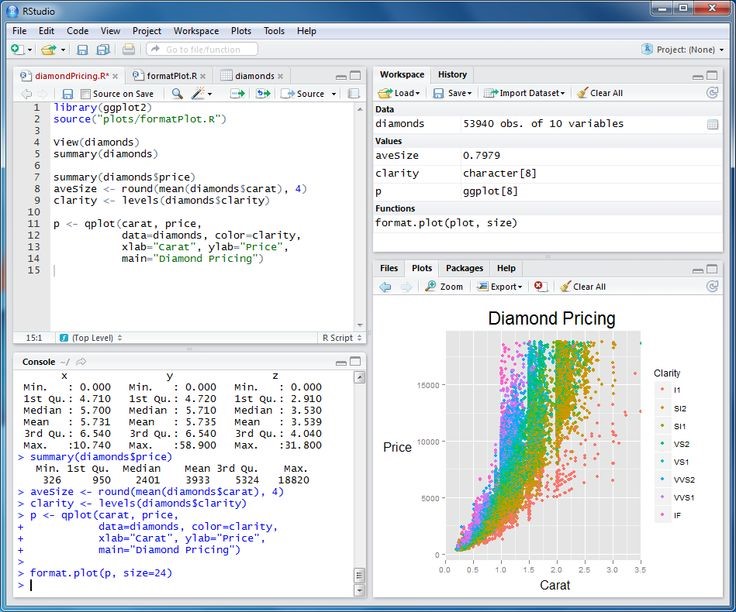
- R-Programming, It’s a free software programming language and software environment for statistical computing and graphics. It compiles and runs on a wide variety of UNIX platforms, Windows and MacOS. The R language is widely used among data miners for developing statistical software and data analysis. One of R’s strengths is the ease with which well-designed publication-quality plots can be produced, including mathematical symbols and formulae where needed.It also provides statistical and graphical techniques, including linear and nonlinear modeling, classical statistical tests, time-series analysis, classification, clustering, and others.
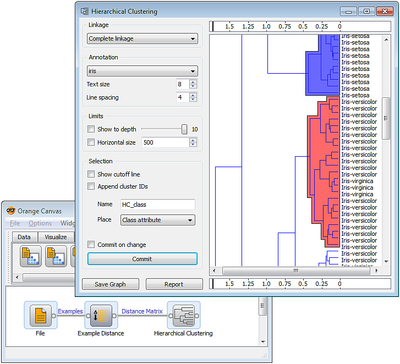
- Orange, a Python-based, powerful and open source tool for both novices and experts. Orange provides statistical distributions, box plots and scatter plots, or dive deeper with decision trees, hierarchical clustering, heatmaps, MDS and linear projections for more interactive data visualization. Their graphic user interface allows you to focus on exploratory data analysis instead of coding, while clever defaults make fast prototyping of a data analysiow extremely easy.
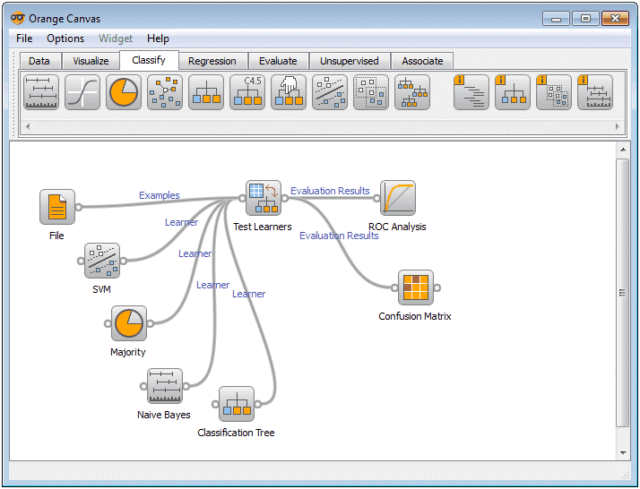
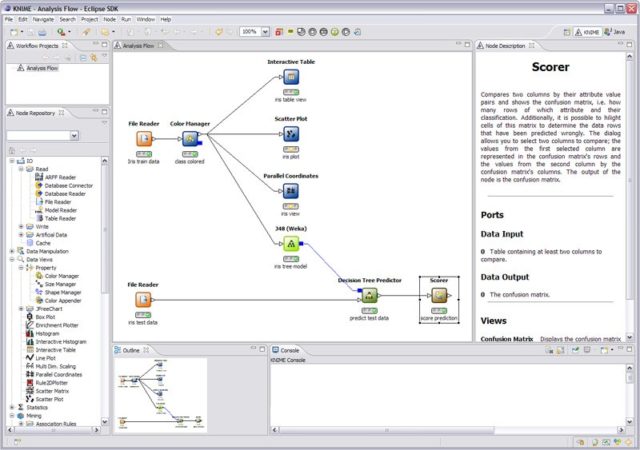
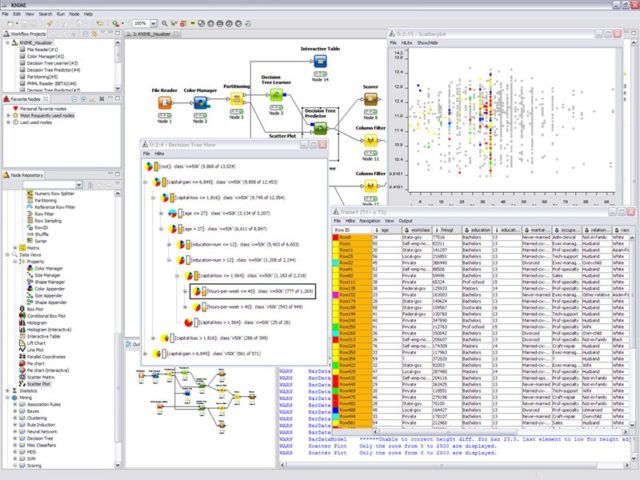
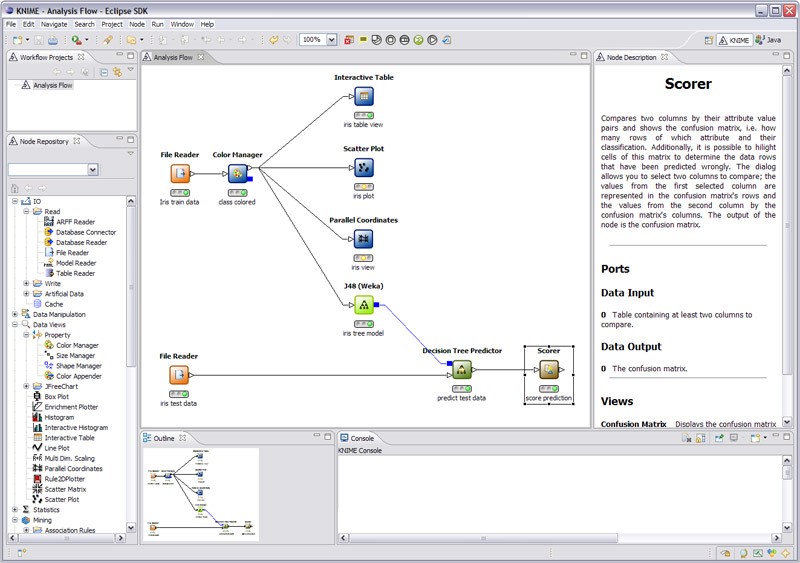
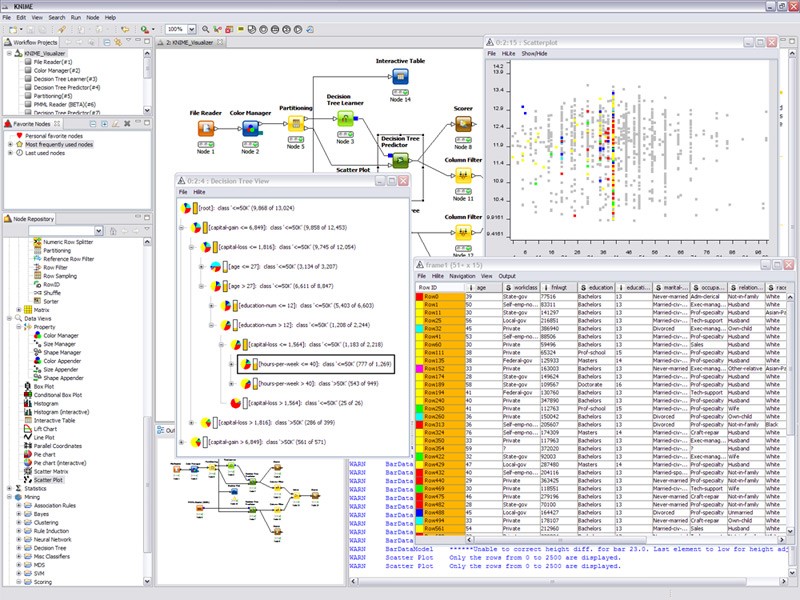
- KNIME does all three main components in data preprocessing, which are extraction, transformation and loading. It gives a graphical user interface to allow for the assembly of nodes for data processing. It is an open source data analytics, reporting and integration platform. KNIME also integrates various components for machine learning and data mining through its modular data pipelining concept and has caught the eye of business intelligence and financial data analysis.
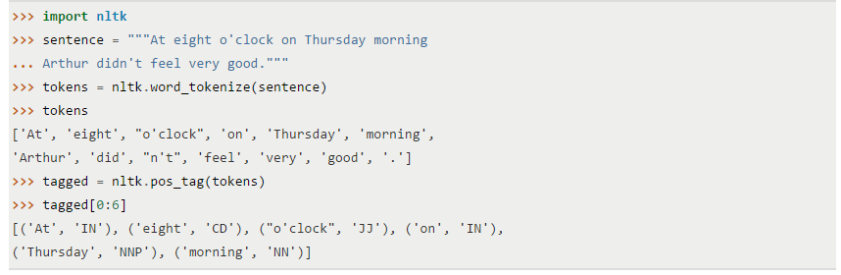
- NLTK provides a pool of language processing tools including data mining, machine learning, data scraping, sentiment analysis and other various language processing tasks. Because it’s written in Python, we can build applications on top of it, customizing it for small tasks. NLTK is available for Windows, Mac OS X, and Linux. Best of all, NLTK is a free, open source, community-driven project. There are several things that we can be done through NLTK:
- Tokenization
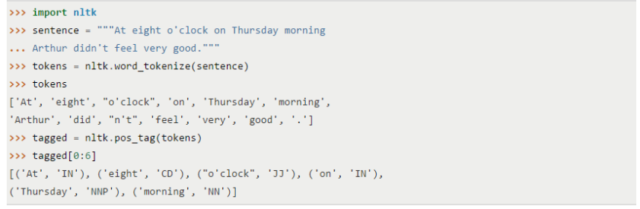
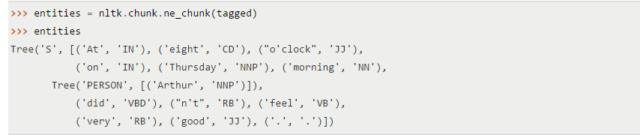
- Identify entities
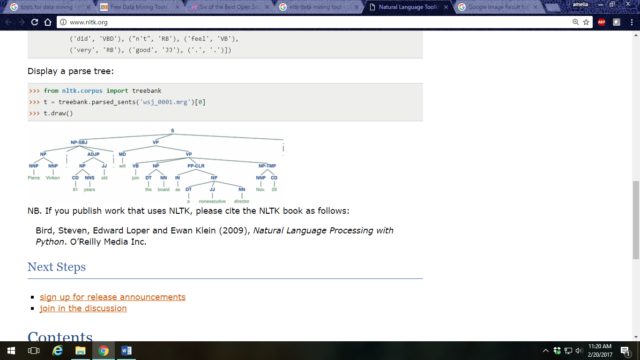
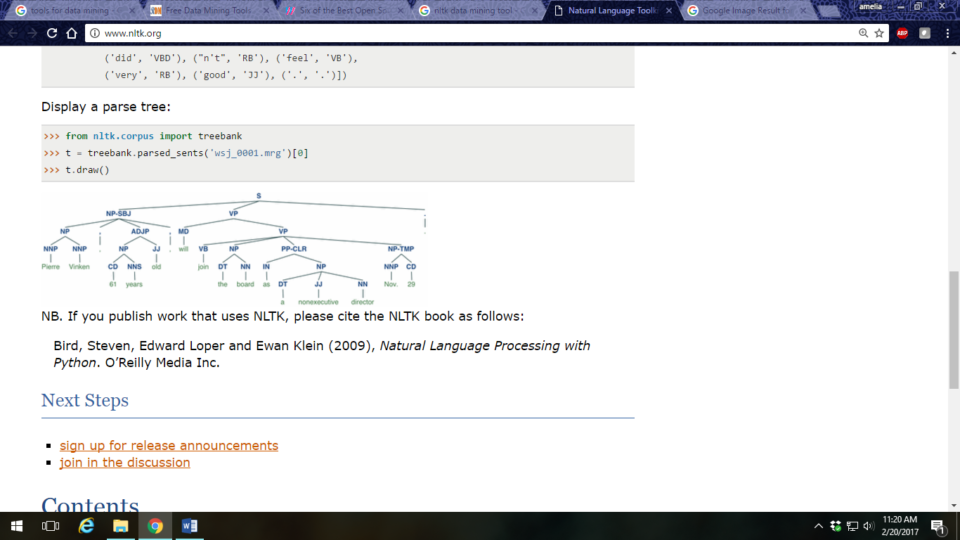
- Display a parse tree
Comments :