

Perbedaan Association, Prediction, and Clustering
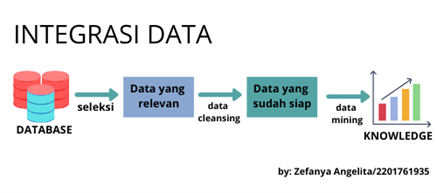
Ketersediaan data yang melimpah dan kebutuhan akan informasi sebagai pendukung pengambilan keputusan untuk membuat solusi bisnis, dan dukungan infrastruktur di bidang teknologi merupakan cikal bakal lahirnya teknologi data mining. Data mining merupakan teknologi yang sangat berguna untuk membantu menemukan informasi yang sangat dibutuhkan dari Gudang data. Data mining adalah kegiatan mengekstrak informasi atau pengetahuan penting dari suatu set data berukuran besar dengan menggunakan teknik tertentu. Data mining melibatkan penggunaan metode atau tool untuk mendeteksi pola dan melakukan suatu tugas prediksi. Dengan menggunakan data yang ada dan relevan, data mining membuat beberapa model untuk mengidentifikasi pola-pola diantara atribut-atribut yang ada di dalam dataset. Beberapa pola tersebut adalah bersifat deskriptif (menjelaskan saling-keterkaitan atau persamaan dan kesamaan diantara berbagai atribut tersebut), dan bersifat prediktif (meprediksi ‘value/hasil’ yang akan terjadi). Pendekatan yang digunakan dalam data mining adalah discovery-based dimana pencocokan pola (pattern matching) dan algorutma yang lain digunakan untuk menentukan relasi-relasi kunci dalam data yang dieksplorasi.
Empat jenis pola utama dalam data mining adalah association, predictions, clustering/segmentation and sequential relationship. Association adalah pengelompokkan hal yang biasanya terjadi bersamaan, misalnya 10 orang membeli susu kental manis, 5 orang dari 10 orang tersebut membeli keju lalu disimpulkan bahwa jika pelanggan membli susu kental manis ia juga akan membeli keju. Selanjutnya prediksi, menjelaskan sifat-sifat dasar kejadian di masa mendatang terhadap peristiwa-peristiwa tertentu berdasarkan apa yang telah terjadi misalnya prediksi harga saham dalma bentuk time series atau rentet waktu. Clustering adalah pengelompokkan hal-hal berdasarkan karakter-karakter yang sudah diketahui atau pengelompokkan data, hasil observasi ke dalam class yang mirip misalnya pengelompokkan konsumen berdasarkan demografis. Sequential relationship yaitu menemukan rangkaian-rangkaian peristiwa misalnya memprediksi seorang customer yang sudah dating untuk hair coloring rambut kemudian akan melakukan treatment untuk merawat rambutnya.
Jika dikelompokkan ke dalam 3 kategori utama adalah prediksi atau prediction, asosiasi atau association, dan clustering. Berdasarkan cara pola-pola tersebut diekstraksi dari data historis, metode dalam data mining bisa diklasifikasikan sebagai supervised maupun unsupervised. Supervised learning, data yang digunakan untuk pelatihan meliputi atribut-atribut deskriptif (misalnya variabel independent atau variabel decision) dan juga atribut class (misalnya variabel output atau variabel hasil). Unsupervised learning, data pelatihan hanya terdiri dari atribut deskriptif. Dalam supervised learning variable yang menjadi target ditentukan sedangkan dalam unsupervised learning variable yang menjadi target tidak ditentukan atau tidak ada.
Associations
Associations (asosiasi) atau ‘association rule learning in data mining’, adalah teknik yang sangat popular dan dikaji dengan baik sekali untuk menemukan hubungan yang menarik diantara berbagai variable dalam database yang sangat besar. Dalam konteks industri retail, ‘association rule mining’ seringkali disebut juga dengan ‘market-basket analysis’. Pada association rule ini tujuannya untuk mencari atribut yang muncul bersamaan dalam satu transaksi. Algoritma dalam asosiasi dilakukan untuk Analisa dengan konsep utama mencari produk mana yang dibeli bersamaan. Turunan dari ‘association rule mining’ yang paling umum digunakan adalah ‘link analysis’ dan ‘sequence analysis’ (analisa urutan aktivitas). Dengan ‘link analysis’, kaitan diantara banyak object yang menarik didapatkan secara otomatis, seperti hubungan antara halaman-halaman web. Dengan ‘sequence mining’, berbagai macam hubungan diteliti berdasarkan urutan kejadian untuk mengidentifikasi ‘associations’ terhadap waktu. Berbagai algorithma yang digunakan dalam ‘association rule mining’ meliputi algorithma Apriori yang sangat terkenal (dimana sekumpulan item yang sering muncul diidentifikasi) dan FP-Growth, OneR, ZeroR, dan Eclat.
Prediction
Prediction dianggap sebagai tindakan yang menjelaskan mengenai masa mendatang. Prediction tentunya berbeda dengan menebak secara sederhana, mempertimbangkan pengalaman, opini, dan informasi lainnya dalam melakukan peramalan. Istilah yang umumnya dikaitkan dengan ‘prediction’ adalah ‘forecasting’. Meskipun banyak orang yang percaya bahwa kedua istilah itu adalah sinonim, tetapi ada perbedaan tipis namun sangat penting diantara keduanya. ’Prediction’ pada umumnya berbasis opini dan pengalaman, ‘forecasting’ berbasis data dan model. Dalam terminology data mining, ‘prediction’ dan ‘forecasting’ digunakan secara sinonim, dan istilah prediksi digunakan sebagai penyajian yang umum. Bergantung pada sifat alami yang akan diprediksikan, ‘prediction’ bisa disebut secara lebih spesifik sebagai ‘classification’ (dimana hal yang diprediksi, seperti ramalan esok, di beri label class misalnya ‘rainy’ or ‘sunny’) atau regresi (dimana hal yang diprediksi, misalnya suhu esok, adalah angka riil misalnya ‘65oF’).
Clustering
Clustering membagi sekumpulan hal (misalnya, objects, events, dll, yang disajikan di database) menjadi segment-segment berdasarkan karakteristik yang serupa. Berbeda dengan ‘classification’, di dalam ‘clustering’ label-label class tidaklah diketahui. Ketika algorithma terpilih memeriksa dataset, mengidentifikasi kesamaan berbagai hal berdasarkan karakteristik-karakteristik nya, saat itulah cluster-cluster dibuat. Setelah cluster-cluster yang ‘masuk akal’ didapatkan, maka bisa digunakan untuk mengklasifikasi dan menginterpretasikan data baru. Tujuan dari clustering adalah membuat kelompok-kelompok dimana anggota kelompok dalam setiap kelompok memiliki kemiripan yang maksimum dan anggota-anggota kelompok di kelompok lain memiliki kemiripan yang minimum. Teknik clustering yang paling banyak digunakan adalah ‘k-means’ (dari statistik) dan ‘self-organizing maps’ (dari machine learning), yang merupakan arsitektur jaringan syaraf yang unik yang dikembangkan oleh Kohonen (1982).
| DATA MINING TASKS & METHODS | DATA MINING ALGORITHMS | LEARNING TYPE |
| Prediction
Classification Regression Time series |
Decision Trees, Naive Bayes Linear/Nonlinear regression Autoregressive, averaging methods |
Supervised Supervised Supervised |
| Association
Market-basket Link Analysis Sequence Analysis |
Apriory, OneR, GA Graph-based matching Apriory algorithm |
Unsupervised Unsupervised Unsupervised |
| Segmentation
Clustering Outlier analysis |
K-means, Expectation max K-means, Expectation maxi |
Unsupervised Unsupervised |
Comments :