

How Does Sentiment Analysis Work?
Sentiment analysis atau analisis sentimen adalah salah satu proses komputasi dengan menganalisis teks digital yang digunakan untuk menentukan apakah kata-kata atau kalimat yang disampaikan memiliki makna atau emosional pesan. Analisis sentiment merupakan salah satu aplikasi yang menerapkan teknologi Natural Language Processing (NLP) yang melatih perangkat lunak komputer untuk memahami teks dengan cara yang mirip dengan manusia. Saat ini, analisis sentimen banyak digunakan untuk mengukur kepuasan pelanggan, brand monitoring, sentiment politik, analisis pasar, pemantauan media sosial, dll.
Dalam analisis sentiment, algoritma dibagi menjadi tiga kelompok
- Ruled-based
Sistem secara otomatis melakukan analisis sentiment berdasarkan pada serangkaian aturan yang dibuat oleh manusia untuk membantu mengidentifikasi subjektivitas, polaritas, atau subjek suatu opini. Aturan-aturan ini dapat mencakup berbagai Teknik NLP yang dikembangkan dalam linguistik misalnya:
- Stemming, tokenization, part of tagging dan parsing.
- Lexicons (daftar kata dan ekspresi)
- Automatic
Metode otomatis ini berbeda dengan ruled-based, tidak bergantung pada aturan yang dibuat secara manual, aturan dibuat dengan machine learning. Tugas analisis sentimen biasanya memodelkan sebagai masalah klasifikasi. Classifier akan melakukan klasifikasi teks dan mengembalikan kategori misalnya positif, negatif, atau netral.
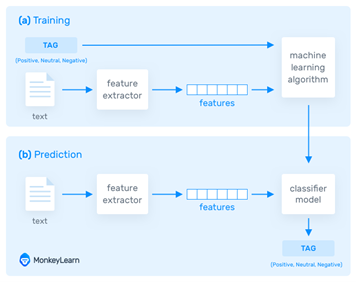
Sumber: https://monkeylearn.com/sentiment-analysis/
Pada proses training (a) model belajar dengan mengaitkan input (misal teks) ke output (tag) yang sesuai berdasarkan sampel pengujian yang digunakan untuk pelatihan. Feature extractor mentransfer input teks ke dalam feature vector. Pasangan feature vector dan tag (misal positif, negative, atau netral) dimasukkan ke dalam algoritma machine learning untuk menghasilkan model. Pada proses prediksi (b), feature extractor digunakan untuk mengubah masukan teks yang tidak terlihat menjadi feature vectors. Feature vectors kemudian dimasukkan ke dalam model, yang menghasilkan tag prediksi (positif, negatif, atau netral).
Pada feature extraction dari teks, langkah pertama pada machine learning text classifier untuk mengubah text extraction atau text vectorization, dan pendekatan klasiknya adalah bag-of-words atau bag-of-ngrams dengan frekuensinya. Baru-baru ini, Teknik untuk feature extraction telah diterapkan berdasarkan word embedding atau dikenal juga dengan word vector. Representasi semacam ini memungkinkan kata-kata dengan makna serupa memiliki representasi serupa, sehingga dapat meningkatkan kinerja classifier. Tahap klasifikasi biasanya melibatkan model statistika misalnya Naïve Bayes Classifier, Logic Regression, Support Vector Machines, atau Neural Networks.
- Hybrid
Pendekatan Hybrid mengkombinasikan elemen yang dibutuhkan dalam rule-based dan Teknik otomatis dalam satu sistem. Keuntungan utama dengan sistem ini adalah hasilnya lebih akurat.
Proses dalam analisis sentimen melibatkan sejumlah langkah penting untuk mengidentifikasi, mengklasifikasikan, dan menganalisis sentimen atau opini dalam teks. Berikut adalah langkah-langkah utama dalam proses analisis sentimen:
- Pengumpulan data teks
Proses dimulai dengan mengumpulkan data teks yang akan dianalisis. Data ini dapat berupa ulasan produk, posting media sosial, komentar, artikel berita, atau teks apa pun yang berisi opini atau sentimen
- Pemrosesan Teks
Data teks kemudian diproses untuk membersihkannya dari informasi yang tidak relevan. Ini mencakup langkah-langkah seperti:
- Tokenisasi: Memisahkan teks menjadi unit-unit yang lebih kecil seperti kata-kata atau frasa.
- Penghapusan Tanda Baca: Menghilangkan tanda baca yang tidak relevan seperti koma, titik, atau tanda seru.
- Stemming atau Lemmatization: Mereduksi kata-kata ke bentuk dasarnya untuk mengatasi variasi kata.
- Ekstraksi fitur
Langkah ini melibatkan ekstraksi fitur-fitur penting dari teks yang akan digunakan dalam analisis sentimen. Beberapa teknik ekstraksi fitur yang umum digunakan meliputi:
- Penghitungan Kata: Menghitung frekuensi kemunculan kata-kata dalam teks.
- TF-IDF (Term Frequency-Inverse Document Frequency): Mengukur seberapa penting suatu kata dalam dokumen tertentu dalam konteks seluruh koleksi dokumen.
- Word Embeddings: Merepresentasikan kata-kata dalam bentuk vektor angka untuk pemrosesan lebih lanjut.
- Pengklasifikasian sentimen
Pengklasifikasian Sentimen adalah inti dari analisis sentimen, dimana teks diklasifikasikan menjadi kategori sentimen tertentu, seperti positif, negatif, atau netral. Ada beberapa metode yang dapat digunakan untuk pengklasifikasian sentimen:
- Analisis Sentimen Berbasis Aturan: Menggunakan aturan-aturan yang telah ditentukan sebelumnya untuk mengklasifikasikan teks. Misalnya, mencocokkan kata-kata kunci positif dan negatif dalam teks.
- Analisis Sentimen Berbasis Mesin Pembelajaran: Menggunakan algoritma pembelajaran mesin untuk mengklasifikasikan teks berdasarkan pola yang dipelajari dari data pelatihan. Contoh algoritma termasuk Naive Bayes, Support Vector Machines, dan Deep Learning.
- Analisis emosi
Opsional, tergantung pada tujuan analisis, langkah ini dapat melibatkan identifikasi emosi spesifik dalam teks. Misalnya, mengidentifikasi apakah teks mengandung rasa senang, kemarahan, atau kesedihan.
- Interpretasi hasil
Setelah sentimen diklasifikasikan, hasil analisis perlu diinterpretasikan. Ini melibatkan pemahaman konteks dan dampak sentimen pada tujuan analisis. Misalnya, jika hasilnya adalah sentimen negatif terhadap produk, perusahaan perlu mempertimbangkan tindakan perbaikan.
- Visualisasi
Visualisasi hasil analisis sentimen dapat membantu pemahaman lebih lanjut dan komunikasi hasil kepada pihak terkait. Grafik, diagram batang, atau peta panas adalah contoh visualisasi yang dapat digunakan.
- Pengembangan Model dan Evaluasi (Opsional)
Jika menggunakan analisis sentimen berbasis mesin pembelajaran, ada kemungkinan ingin mengembangkan model sendiri dan melakukan evaluasi kinerjanya. Hal ini melibatkan pelatihan model pada data pelatihan, validasi model pada data validasi, dan pengukuran kinerja menggunakan metrik seperti akurasi, presisi, dan recall.
- Penerapan Berkelanjutan (Opsional)
Dalam banyak kasus, analisis sentimen bukanlah proses satu kali. Untuk aplikasi bisnis atau pemantauan berkelanjutan, analisis perlu dijalankan secara berkala pada data yang baru masuk.
Proses analisis sentimen dapat sangat bervariasi tergantung pada sumber data, tujuan analisis, dan teknik yang digunakan. Penggunaan algoritma berbasis machine learning, khususnya deep learning, telah meningkatkan akurasi analisis sentimen, tetapi juga memerlukan sumber daya komputasi yang lebih besar dan pemahaman yang lebih mendalam tentang model yang digunakan.
Sumber:
- https://monkeylearn.com/sentiment-analysis/
- https://awario.com/blog/sentiment-analysis/
- https://aws.amazon.com/what-is/sentiment-analysis/