

K-Fold Cross-Validation
Terdapat beberapa jenis Cross-Validation namun menurut Sinan Ozdemir (2017) yang paling akurat adalah K-Fold Validation, K-Fold Validation memberikan hasil yang paling akurat dan efektif untuk diterapkan di data training yang berbeda di dataset yang sama. Menurut Refailzadehet et al (2009), bagian gelap dari table 10-Fold Validation mewakilkan data training dan bagian terang dari table 10-Fold Validation mewakilkan data testing Metode ini dapat digunakan untuk mengukur parameter algoritma yang berbeda, dan pemilihan beberapa model yang telah ditentukan sebelumnya, namun K-Fold Validation memiliki kekurangan yaitu estimasi performa memiliki sampel yang kecil
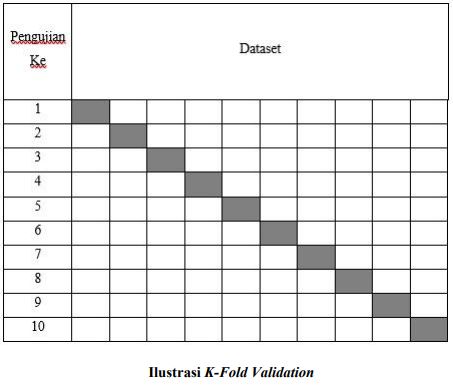
Putih : Data Pelatihan
Hitam : Data Pengujian
Tahap untuk melakukan K-Fold Validation adalah sebagai berikut, data yang ada dibagi-bagi menjadi segmen yang berukuran sama atau mendekati, Selanjutnya data training untuk iterasi atau pengulangan dan data validasi dilakukan, sehingga dalam setiap iterasi lipatan data yang berbeda diperlukan untuk validasi sedangkan k1 lipatan yang tersisa digunakan untuk pembelajaran. Data dibagi menjadi tingkatan sebelum melakukan proses K-fold, menata ulang data untuk setiap lipatan data merupakan perwakilan yang sesuai dari keseluruhan data yang ada. Jadi setiap lipatan yang akan dilakukan terwakili oleh data keseluruhan yang ada, setiap flip yang dilakukan merupakan data terbaik yang telah diberikan berdasarkan persentase perwakilan data.
Referensi:
Refaeilzadeh, Payam & Tang, Lei & Liu, Huan. (2009). Cross-Validation. Encyclopedia of Database Systems. 532–538. 532-538. 10.1007/978-0-387-39940-9_565.
Comments :