

Data Mining – Text Categorizing
Data Mining adalah proses menemukan anomali, pola, dan korelasi dalam kumpulan data besar untuk memprediksi hasil. Dengan menggunakan berbagai teknik, Anda dapat menggunakan informasi ini untuk meningkatkan pendapatan, memotong biaya, meningkatkan hubungan pelanggan, mengurangi risiko, dan banyak lagi. Data Mining berawal dari Proses penggalian data untuk menemukan koneksi tersembunyi dan memprediksi tren masa depan memiliki sejarah yang panjang. Kadang-kadang disebut sebagai “penemuan pengetahuan dalam database,” istilah “data mining” tidak diciptakan hingga tahun 1990-an. Tetapi fondasinya terdiri dari tiga disiplin ilmu yang saling terkait: statistik (studi numerik tentang hubungan data), kecerdasan buatan (kecerdasan mirip manusia yang ditampilkan oleh perangkat lunak dan / atau mesin) dan pembelajaran mesin (algoritme yang dapat belajar dari data untuk membuat prediksi). Apa yang lama adalah baru lagi, karena teknologi penambangan data terus berkembang untuk mengimbangi potensi data besar yang tak terbatas dan daya komputasi yang terjangkau.
Salah Satu sub kelas pada data mining adalah Text Mining. Text Mining adalah proses mengubah teks tidak terstruktur menjadi format terstruktur untuk mengidentifikasi pola yang bermakna dan wawasan baru. Dengan menerapkan teknik analitik tingkat lanjut, seperti Naïve Bayes, Support Vector Machines (SVM), dan algoritme pembelajaran mendalam lainnya, perusahaan dapat menjelajahi dan menemukan hubungan tersembunyi di dalam data tidak terstruktur mereka. Pada Text Mining terdapat istilah Text Categorization.
Text Categorization adalah proses mengkategorikan teks ke dalam kelompok terorganisir. Dengan Menggunakan Metode Natural Language Processing atau yang biasa disebut NLP, Text Categorization dapat menganalisis teks secara otomatis dan kemudian menetapkan sekumpulan tag atau kategori yang telah ditentukan sebelumnya berdasarkan kontennya.
Terdapat tiga pendekatan yang dapat dilakukan pada text Categorization, yaitu:
- Rule-Based Systems
- Adalah Pendekatan mengklasifikasikan teks ke dalam kelompok terorganisir dengan menggunakan seperangkat aturan linguistik buatan tangan
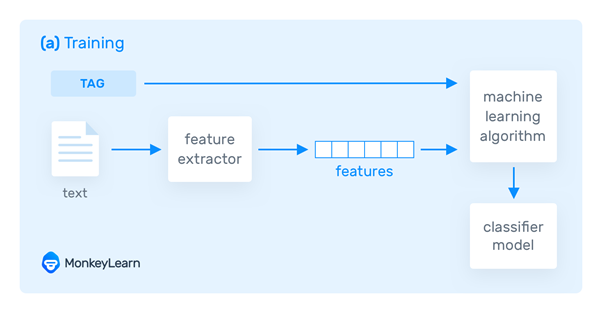
- Machine learning Based Systems
- membuat klasifikasi berdasarkan pengamatan sebelumnya.
- Dengan menggunakan contoh yang diberi label sebelumnya sebagai data pelatihan, algoritme pembelajaran mesin dapat mempelajari asosiasi yang berbeda antara bagian teks dan bahwa keluaran tertentu (yaitu tag) diharapkan untuk masukan tertentu (yaitu teks).
- Hybrid Systems
- Kombinasi dari pendekatan machine learning dan rule-based approach.

References
| [1] | S. Simsek, U. Kursuncu, E. Kibis, M. A. Abdellatif and A. Dag, “A hybrid data mining approach for identifying the temporal effects of Variables Associated with breast cancer survival,” Elsevier, vol. 139, pp. 1-13, 2020.
https://monkeylearn.com/text-classification/ |