Arsitektur Data Modern 2
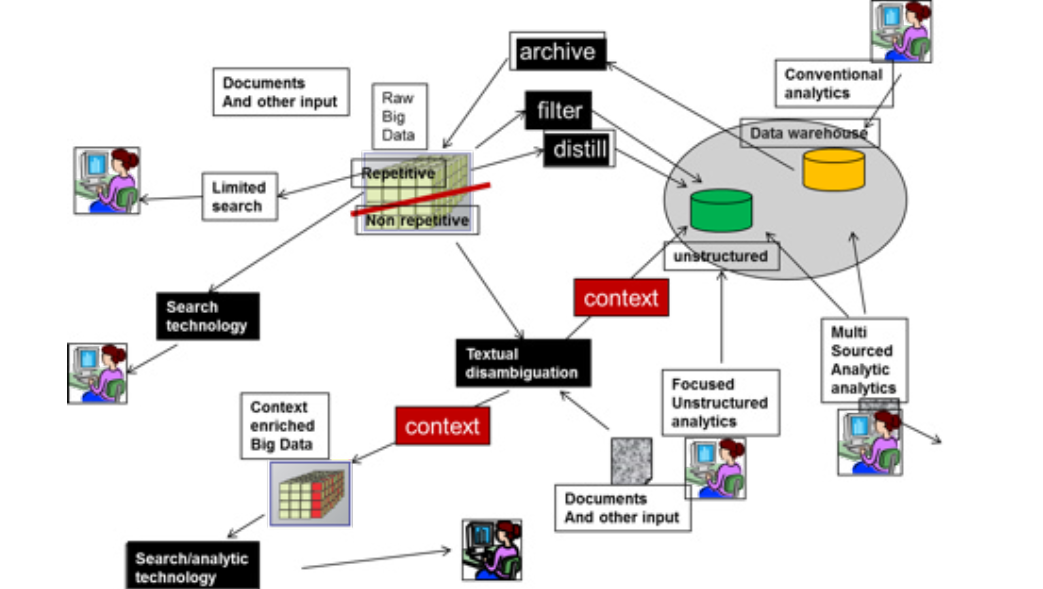
BIG DATA AND A DATA WAREHOUSE CAN COEXIST AND WORK IN HARMONY
HARMONIOUS COEXISTENCE
Terlepas dari kebingungan yang sampaikan oleh vendor Big Data, ada kebutuhan untuk memahami bagaimana Big Data dan data warehouse bisa hidup berdampingan. Ada kebutuhan dari sudut pandang arsitektural untuk memiliki “gambaran besar” yang menguraikan bagaimana Big Data dan data warehouse dapat hidup berdampingan dan bekerja secara harmonis dan secara konstruktif.
REPETITIF / NON-REPETITIF DATA
Gambar – arsitektur umum – menunjukkan banyak fitur arsitektur utama. Fitur arsitektur utama pertama yang ditunjukkan adalah Big Data dibagi menjadi dua subdivisi besar – kejadian berulang dari data dan kejadian data yang tidak berulang.
Kejadian berulang data terdiri dari data dimana struktur data yang sama berulang berkali-kali.
Ada banyak contoh data repetitif yang berbeda. Data berulang yang khas terdiri dari rekaman kaset, catatan detail rekaman telepon, data klik stream, data metering, data meteorologi, dan lain-lain.
Dalam data berulang, struktur data yang sama terjadi berulang-ulang. Dalam banyak kasus, data berulang adalah data yang ditulis oleh mesin atau diproduksi oleh pemrosesan analog.
Data non-repetitif juga memiliki banyak contoh. Beberapa contoh data non-repetitif meliputi email, percakapan call center, komentar survei, percakapan di help desk, data klaim garansi, dan lain-lain. Dalam data non-repetitif, hanya kebetulan jika data atau struktur data yang sama pernah terjadi dua kali. Hampir di setiap kasus, data non-repetitif adalah data berbasis tekstual yang dihasilkan oleh kata-kata tertulis atau kata yang diucapkan.
“Pembagian Besar”
Perbedaan antara data berulang dan data non-repetitif di Big Data telah disebut “Great Divide”.
Ada sejumlah perbedaan antara cara kedua jenis data ini perlu ditangani. Penyimpanan data, penulisan data, dan pembacaan data semua memerlukan pendekatan yang sangat berbeda dan teknologi yang sangat berbeda.
PEMODELAN DATA
Salah satu perbedaan menarik antara data berulang dan data non-repetitif adalah bagaimana data dimodelkan. Data berulang biasanya dimodelkan oleh model data ERD (entity relationship diagram). Data non-repetitif dimodelkan dengan cara yang sama sekali berbeda dengan penggunaan taksonomi dan ontologi.
Dengan ERD perancang bebas mengubah data agar sesuai dengan model. Tapi dengan taksonomi dan ontologi, data base TIDAK PERNAH berubah. Sebagai konsekuensinya, jika ada kebutuhan untuk melakukan perubahan, taksonomi atau ontologi yang berubah, bukan data dasar.
Kedua jenis model data bisa (dan biasanya harus) dibangun secara umum. Ada sedikit perbedaan antara model yang dibangun untuk industri. Sebagai konsekuensinya, model generik – setidaknya sebagai titik awal – sangat disarankan.
TEXTUAL DISAMBIGUATION
Jalur khas untuk data non-repetitif yang harus ditangani dan dikelola adalah melalui proses data non-berulang melalui teknologi yang dikenal sebagai “disosiasi teknual”. Data non-repetitif dibaca dan diformat ulang dan – yang lebih penting lagi dikontekstualisasikan. Agar dapat mengetahui data non-repetitif, data harus memiliki konteks data yang ditetapkan. Tugas diselingi tekstual adalah untuk mendapatkan dan mengidentifikasi konteks data yang tidak berulang. Dalam banyak kasus, konteks data non-repetitif lebih penting daripada data itu sendiri. Bagaimanapun, data non-repetitif tidak dapat digunakan untuk pengambilan keputusan sampai konteksnya terbentuk.
KONTEKS BESAR DATA BESAR
Setelah konteks data non-repetitif terbentuk, data dapat dikirim ke salah satu dari dua tempat.
Data kontekstual dapat dikirim ke lingkungan analisis dan dikombinasikan dengan data gudang data lainnya, atau data yang dapat dikontekstualkan dapat dikirim kembali ke lingkungan Data Besar. Jika data kontekstual dikirim kembali ke lingkungan Data Besar, data dikirim kembali sebagai “data yang diperkaya konteks”.
Ada kemungkinan data kontekstual begitu banyak sehingga tidak dapat dikirim ke lingkungan data warehouse karena banyaknya data. Namun, jika data kontekstual dikirim ke gudang data klasik, pemrosesan yang berlangsung di atasnya dapat dilakukan dengan alat analisis standar seperti Tableau, Qlik, Business Objek, SAS, Excel, dan sebagainya.
Sumber : W.H. Inmon